System Design Question: Designing a Facebook Feature to Show Friends' Locations
System Design Question: Designing a Facebook Feature to Show Friends' Locations
Designing a feature to display friends' locations on Facebook is a popular and insightful system design problem frequently asked in Meta's engineering interviews. It tests your ability to manage complex distributed systems, scalability, privacy, and user experience concerns. Below, we'll walk through a structured, detailed approach to tackling this problem, highlighting key decisions, trade-offs, and the reasoning behind architectural choices to help you excel in your system design interviews.
1. Clarify and Understand the Problem
Clearly outline the scope, including:
- Purpose: Enable social connectivity by displaying friends’ locations on a map.
- Data Types: Profile-based location (hometown), real-time or recent location updates.
- Privacy Controls: Allow granular user control over location visibility—public, friends, specific friends, or private.
- Scale: Must efficiently support billions of users.
Tip: Always ask interviewers clarifying questions to show deep understanding and precision.
2. Functional Requirements
- Location Display:
- Map with pins representing friends' locations.
- Respect user-defined privacy settings.
- Prioritize the latest current location; fallback to profile location if needed.
- Data Management:
- Maintain location data (current/profile).
- Store friendship data for efficient retrieval and visibility checks.
- User Interaction:
- Allow manual location updates or opt-in/out functionality.
- Provide clear messaging if friends' locations are unavailable due to privacy settings.
Tip: Clearly distinguishing between essential and nice-to-have requirements showcases your product thinking.
3. Back-of-the-Envelope Calculations
Estimations:
- Total Users: ~3 billion; Daily Active Users (DAU): ~2 billion
- Avg. Friends per User: ~200
- Daily Users Accessing Feature: ~500 million
- Daily Friend Location Checks: 500M × 200 = 100 billion checks/day
- Avg Requests Per Second (RPS): ~1.16M RPS (Peak: ~5.8M RPS)
These calculations underscore the necessity of scalable architecture, effective caching, and optimized data retrieval.
Tip: Always perform rough calculations to demonstrate practical considerations for scalability.
4. Non-Functional Requirements
- Scalability: Adapt to growth seamlessly.
- Latency: Low response times (sub-200ms ideal) for smooth UX.
- Availability: 99.99% uptime; fault-tolerance through redundancy.
- Privacy: Strict enforcement of data visibility rules.
- Consistency vs. Availability: Prioritize availability with eventual consistency for less critical updates (e.g., current location).
Tip: Discuss trade-offs explicitly (e.g., eventual consistency is acceptable for location updates).
5. API Design
Sample APIs:
- getFriendsLocations(userId) → Fetch visible friends’ locations.
- updateUserLocation(userId, locationId, visibility) → Update user location and privacy.
- getPrivacySettings(userId) → Retrieve user's visibility preferences.
Considerations:
- Version APIs for backward compatibility.
- Include pagination or incremental fetching for friends' lists to manage large datasets.
6. Data Model
Entities and key attributes:
- User: user_id, name
- Location: location_id, latitude, longitude, type (profile/current)
- User_Location: user_id, profile_location_id, current_location_id, timestamps
- Friendship: user_id, friend_id, status
- Privacy: user_id, location_type, visibility, specific_friends
Consider indexing on user_id and friend_id for rapid lookups.
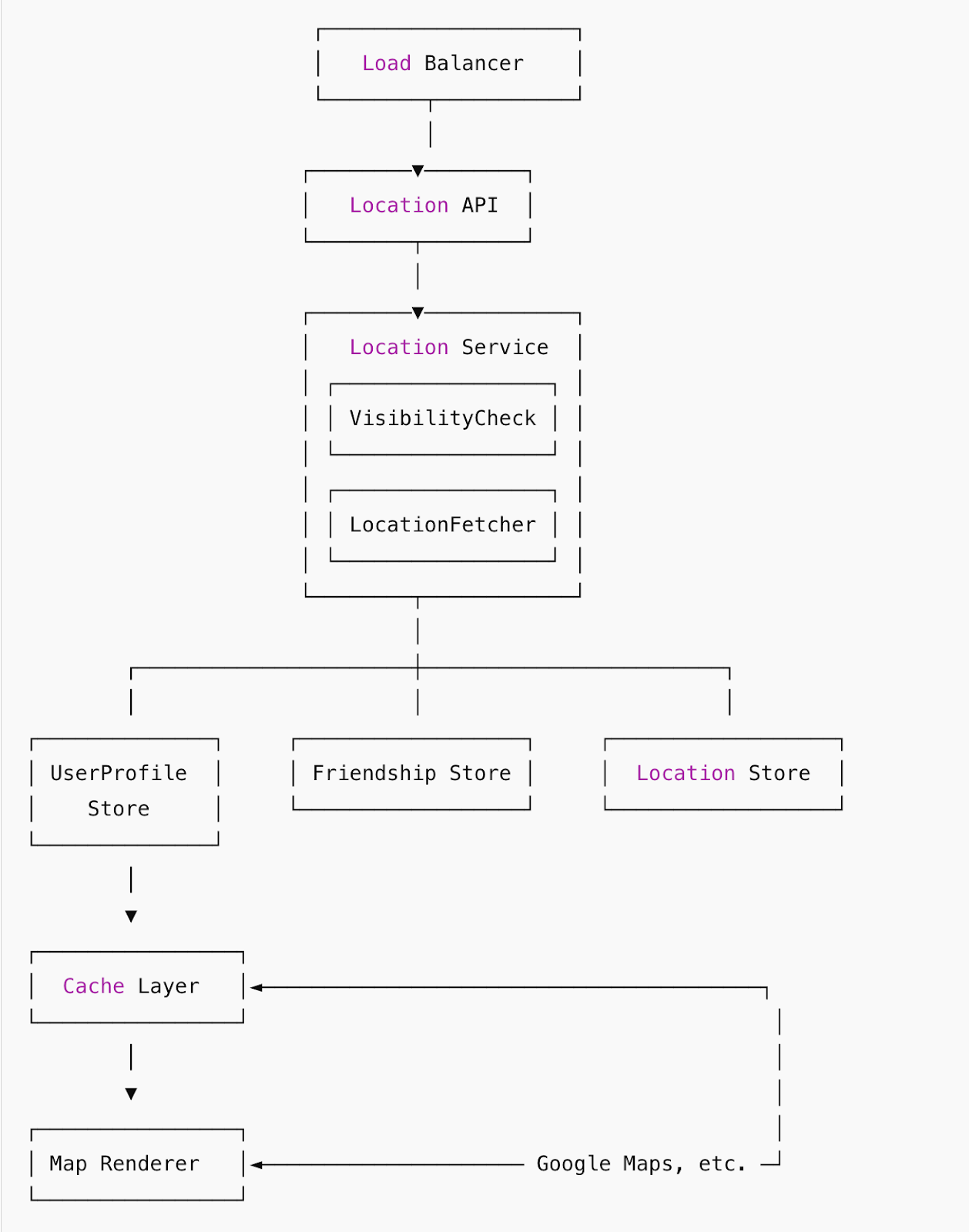
7. High-Level Architecture and Reasoning
Key Components and Reasons:
- Load Balancer: Distributes incoming user requests across multiple servers to prevent bottlenecks, enhancing availability and fault tolerance.
- Location API Server: Centralizes processing of location data requests, ensuring consistent application of business logic.
- Location Service:
- Visibility Checker: Enforces privacy settings to maintain user trust.
- Location Fetcher: Optimizes queries and efficient data access patterns.
- Map Rendering Service: Offloads computationally intensive rendering tasks from client devices, ensuring consistent UX.
- Storage Systems:
- User Profile Store (NoSQL): Offers scalability and flexibility for diverse user data.
- Friendship Store (Graph Database or NoSQL): Efficiently models complex friend relationships.
- Location Store (Relational Database with Spatial Indexing): Enables efficient spatial querying.
- Cache Layer (Redis): Reduces latency and database load by caching frequent requests.
8. Database Choices
- User Profile Store: NoSQL (e.g., DynamoDB) for scalability and flexible schema.
- Friendship Store: Graph database (e.g., Neo4j) or NoSQL for fast friend lookups.
- Location Store: Relational database (e.g., MySQL) with spatial indexing for coordinates.
- Cache Layer: Redis for low-latency access to visible friends’ locations.
9. Location Retrieval Process
When a user opens the “Friends’ Locations” feature:
- Request Received: The Location API receives getFriendsLocations(userId).
- Friend List Retrieval: Query the Friendship Store for the user’s friends (status = 'accepted').
- Location and Privacy Check:
- Fetch each friend’s User_Location and Privacy data.
- Filter locations based on visibility (e.g., 'friends' includes requester, 'specific_friends' checks list).
- Coordinate Lookup: For visible locations, fetch latitude/longitude from the Location Store.
- Caching: Store results in Redis, keyed by user_id, with TTL (e.g., 5 minutes).
- Response Delivery: Return location data to the API, which sends it to the Map Renderer.
- Map Display: Client renders a map with pins, using clustering for dense areas.
10. Ethical Considerations
- Privacy: Enforce strict visibility checks to prevent data leaks.
- User Control: Allow easy opt-out and clear settings visibility.
- Accuracy: Ensure locations reflect user intent, not inferred data.
Conclusion
Designing a feature to show friends’ locations on Facebook requires balancing scalability, privacy, and usability. This solution leverages distributed stores, caching, and a map-based UI to deliver a seamless experience for billions of users. By practicing this structured approach, you’ll be well-prepared for Meta’s system design interviews, showcasing your ability to design robust, user-focused systems.
Potential Questions Asked by Interviewers
Q1: How does the Location Service enforce privacy?
- Answer:
- The Visibility Checker component evaluates each friend’s privacy settings:
- For 'public,' the location is always visible.
- For 'friends,' it checks if the requester is in the friend list (via Friendship Store).
- For 'specific_friends,' it queries a sub-table to confirm inclusion.
- For 'only_me,' the location is hidden.
- This logic runs in-memory for speed, with precomputed visibility cached in Redis where possible.
- Technology: Uses a rule engine or simple conditional logic, backed by DynamoDB for settings storage.
Q2: Why choose Redis for caching?
- Answer:
- Low Latency: Redis’s in-memory storage ensures sub-millisecond access, critical for real-time map rendering.
- Simplicity: Key-value pairs (e.g., user:1234:friends_locations) match the need to store precomputed location lists.
- Scalability: Can scale horizontally with clustering, handling peak RPS.
- Trade-off: Limited persistence is acceptable since data can be rebuilt from source stores if needed.
Q3: How does data synchronization work between DynamoDB and Redis?
- Answer:
- Change Data Capture (CDC):
- DynamoDB Streams capture updates to User_Location or Privacy.
- Message Queue:
- Events are published to Kafka for asynchronous processing.
- Location Transformer:
- Consumes Kafka messages, recalculates visible locations for affected users, and updates Redis.
- Redis Update:
- Writes new location data with TTL, ensuring freshness.
- Example:
- User A updates their current location to “San Francisco.”
- CDC triggers a Kafka event.
- Transformer fetches A’s friends, checks visibility, and updates Redis entries like user:friendB:friends_locations.
- Benefits: Near real-time updates, fault tolerance via Kafka buffering.
Q4: How are location coordinates stored and queried efficiently?
- Answer:
- Storage: In the Location Store (e.g., MySQL), use a spatial index (e.g., R-tree) on latitude and longitude.
- Querying: For a user’s friends, batch fetch coordinates with a single query:
SELECT location_id, latitude, longitude
FROM Locations
WHERE location_id IN (friend_location_ids);
Features in Redis: Store as a JSON object, e.g.:
Key: user:1234:friends_locations
Value: {
"friend_1": {"lat": 37.7749, "lon": -122.4194, "name": "San Francisco"},
"friend_2": {"lat": 40.7128, "lon": -74.0060, "name": "New York"}
}
- Process:
- Location Service fetches friend IDs and their visible location_ids.
- Queries Location Store for coordinates.
- Caches result in Redis for subsequent requests.
Q4: Are there any other design alternatives for the Location Retrieval Process?
Yes, there are several design alternatives for the Location Retrieval Process in the "Friends' Locations" feature on Facebook. The original design outlined in the blog uses a straightforward approach: fetching friend lists, checking visibility, retrieving coordinates, caching results, and rendering them on a map. Below, I’ll explore alternative designs, each with different trade-offs in terms of scalability, latency, complexity, and privacy enforcement. These alternatives could come up in a system design interview at Meta, where interviewers often probe for creativity and optimization.
Alternative 1: Precomputed Location Aggregation with Batch Processing
Concept
Instead of computing visible friends’ locations on-demand for each request, precompute and store aggregated location data periodically (e.g., every 5 minutes) in a materialized view or cache. This shifts the workload from real-time queries to batch processing.
Process
Batch Job:
- A scheduled job (e.g., Apache Spark) runs periodically.
- For each user, it queries the Friendship Store, User Profile Store, and Location Store to determine visible friends’ locations based on privacy settings.
- Results are stored in a precomputed table (e.g., DynamoDB) or cache (e.g., Redis) keyed by user_id.
Request Handling:
- When a user requests getFriendsLocations(userId), the Location API directly fetches the precomputed data from the cache or table.
- No real-time visibility checks or coordinate lookups are needed.
Map Display:
- The Map Renderer uses the precomputed coordinates to display pins.
Pros
- Low Latency: Requests are served from cache with minimal computation, reducing response time.
- Scalability: Offloads real-time processing to batch jobs, handling peak loads better.
- Simplicity: API logic is reduced to a single lookup.
Cons
- Staleness: Locations may be outdated (e.g., up to 5 minutes old), missing recent updates.
- Storage Overhead: Precomputing for billions of users requires significant storage (e.g., 2B users × 200 friends × ~100 bytes/location ≈ 40TB per snapshot).
- Complexity: Managing batch jobs and ensuring data consistency (e.g., handling mid-batch updates) adds overhead.
When to Use
- Ideal for scenarios where low latency is critical, and slight staleness is acceptable (e.g., profile locations that change infrequently).
Alternative 2: Event-Driven Real-Time Updates with Pub/Sub
Concept
Use an event-driven architecture where location updates trigger real-time propagation to affected users’ caches via a pub/sub system (e.g., Kafka or Redis Pub/Sub). This ensures freshness while avoiding on-demand computation for every request.
Process
Event Trigger:
- When a user updates their location or privacy settings (via updateUserLocation), an event is published to a Kafka topic (e.g., location_updates).
Event Processing:
- A Location Transformer service subscribes to the topic.
- For each event, it identifies affected friends (via Friendship Store), checks visibility, and updates their cached location views in Redis.
- Cache key: user:friend_id:visible_locations.
Request Handling:
- getFriendsLocations(userId) retrieves the user’s friends’ locations from Redis, aggregating precomputed entries.
Map Display:
- Coordinates are sent to the Map Renderer for display.
Pros
- Freshness: Near real-time updates ensure the map reflects the latest data.
- Efficiency: Avoids redundant visibility checks per request by pushing updates proactively.
- Scalability: Kafka’s partitioning handles high event throughput.
Cons
- Complexity: Requires managing a pub/sub system and ensuring event delivery reliability.
- Cache Inconsistency: Partial updates or failures in event processing could lead to stale or missing data.
- Latency Spike: Initial cache population for new users might require a fallback to on-demand querying.
When to Use
- Best for dynamic environments where current locations change frequently (e.g., manual updates or check-ins), and users expect real-time accuracy.
Alternative 3: Graph-Based Retrieval with In-Memory Processing
Concept
Leverage a graph database (e.g., Neo4j) to store friendships and location visibility as a graph, performing traversal and filtering in-memory for each request. This eliminates separate stores and joins, optimizing for relationship-heavy queries.
Process
Data Model:
- Nodes: Users and Locations.
- Edges: FRIENDS_WITH (bidirectional), HAS_LOCATION (with visibility properties like 'friends' or 'specific_friends').
Request Handling:
getFriendsLocations(userId) triggers a graph query:
- Traverse FRIENDS_WITH edges from the user node.
- Filter HAS_LOCATION edges based on visibility rules (e.g., check if requester is in the friend list).
- Return location nodes with coordinates.
Caching:
- Results cached in Redis to avoid repeated traversals.
Map Display:
- Coordinates are rendered on the map.
Pros
- Performance: Graph traversals are fast for relationship queries, avoiding costly joins across stores.
- Flexibility: Easily extends to complex visibility rules (e.g., “friends of friends”).
- Consistency: Single source of truth reduces synchronization issues.
Cons
- Scalability Limit: Graph databases may struggle with billions of nodes and edges unless heavily sharded.
- Cost: In-memory processing and storage are expensive at Facebook’s scale.
- Complexity: Requires expertise in graph query optimization (e.g., Cypher).
When to Use
- Suitable for smaller-scale deployments or when friend networks and visibility rules are highly interconnected and dynamic.
Recommendation
- Default Choice: The Event-Driven Real-Time Updates approach strikes a balance between freshness, scalability, and manageable complexity. It aligns with Meta’s real-time systems expertise (e.g., News Feed) and ensures up-to-date locations without overloading servers.
- Fallback: For cost-sensitive scenarios, the Precomputed Aggregation approach works well, trading freshness for lower latency and simpler request handling.
- Avoid: The Client-Side Filtering approach, while innovative, introduces too many security and complexity risks for a production system at this scale.